Cet article est un rapport de compétition Kaggle Google Brain - Ventilator Pressure Prediction.
Kaggle est une plateforme web organisant des compétitions en science des données. Sur cette plateforme, les entreprises proposent des problèmes en science des données et offrent un prix aux datalogistes obtenant les meilleures performances. L'entreprise a été fondée en 2010 par Anthony Goldbloom. (Source Wikipedia ).
Problématique
Nous avons choisi de participer a la compétition “Ventilator Pressure Prediction”. Le but de cette compétition est de produire un modèle capable de simuler le comportement des patients sous ventilation artificielle. Avoir une simulation numérique permettra d'améliorer la régulation des appareils respiratoires.
Compétition:
https://www.kaggle.com/c/ventilator-pressure-prediction
Notebook:
https://www.kaggle.com/manuelmasiello/ventilator-pressure-prediction-using-cnn-lstm/notebook

Etudes des données
Les données sont de type time series. Elles sont composées de 75450 séquences de respirations d’une taille toujours égale de 80 data points. Ces séquences sont des enregistrements de pression ainsi que des consignes données aux appareils respiratoires. Voici la liste des champs et l’explication de leurs valeurs.
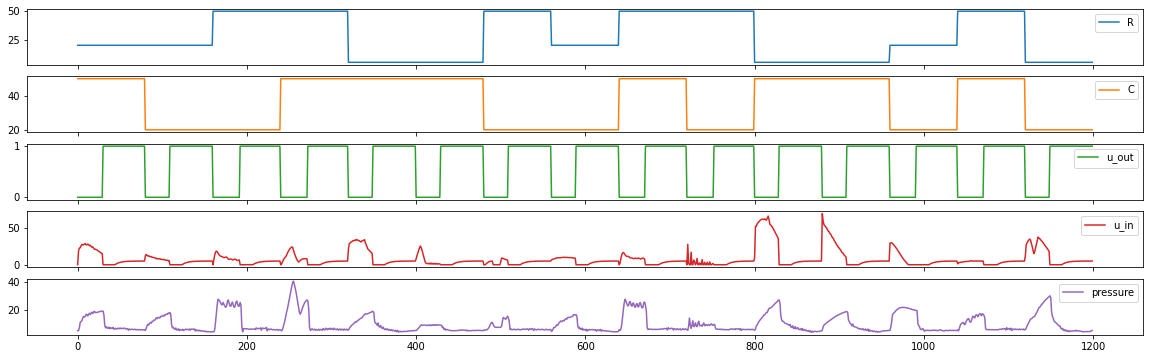
Courbes des features R, C, u_out, u_in et pressure.

La première séquence du jeu de données. A gauche la période d'inspiration, à droite la période d’expiration.

Schéma de fonctionnement de l'expérience ayant donné les données du dataset.
Préparation des données
Normalisation des données
Nous appliquons l’algorithme sklearn.preprocessing.MinMaxScaler pour normaliser et borner les colonnes entre 0 et +1.
Extrait des données normalisées.
Séquençage
Les données vont être groupées par “breath_id” dans des tableaux à 3 dimensions.
Évaluation
Pour évaluer le modèle, nous utiliserons une validation simple d’un groupe d'entraînement de 69414 séquences (92%) et d’un groupe de test de 6036 séquences (8%). Par ces proportions, nous cherchons à vérifier que l’apprentissage se déroule bien plutôt que d'évaluer la qualité de la prédiction.
Modèle proposé
La taille fixe des séquences nous permet d’envisager l’usage d’un réseau de neurones convolutifs (CNN) pour abstraire l’information via des kernels de convolution. En utilisant les paramètres du layer padding='same' et strides=2 nous pouvons réduire la taille en sortie du layer par 2. La taille des séquences, 80, nous permet d’envisager 4 couches d’abstraction avec réduction de taille (40, 20, 10, 5).

A la sortie de la dernière couche de convolution, nous avons une représentation abstraite du signal. Pour prédire la pression, nous devons dé-abstraite le signal avec des couches de convolution inverse. La taille des kernels, et le nombre de kernels ont été fixés empiriquement par l’usage de la librairie Keras Tuner. Pour finir, nous ajoutons un couche Dropout 0.1 ainsi qu’une couche Dense pour avoir une sortie avec la shape (80, 1).
Apprentissage
Nous avons utilisé différentes stratégies pendant l’apprentissage. Nous commençons l’apprentissage avec un “learning rate” de “0.00018”.
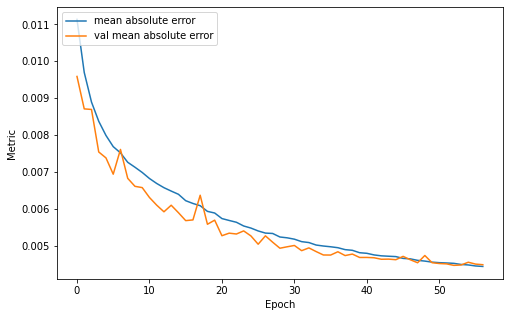
Courbe d’apprentissage
Résultats
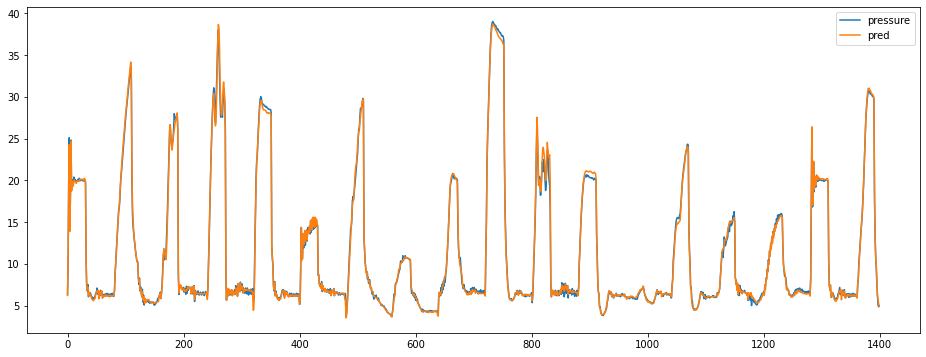
Extrait de courbe. “pressure” en bleu et la prédiction en orange.
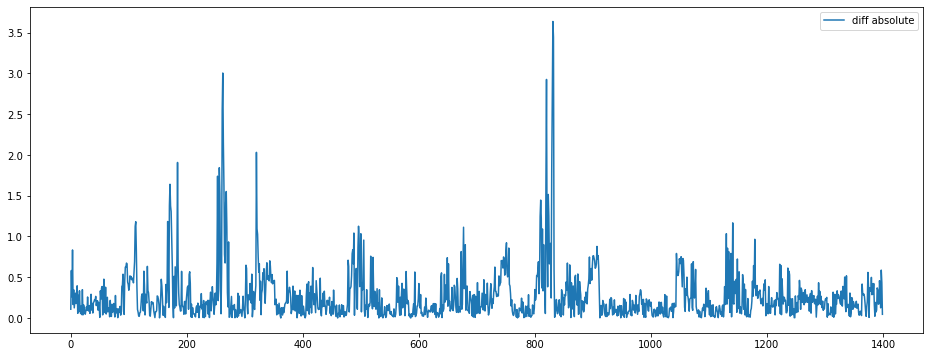
Extrait de courbe. Différente en valeur absolue entre la prédiction et la “pressure”.
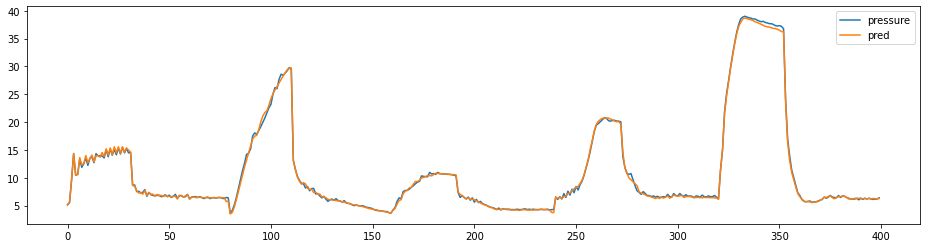
Trois séquences quelconques. “pressure” en bleu et la prédiction en orange.
Histogramme de la différence entre la prédiction et la “pressure”.

Axe d’amélioration
L'évaluation simple peut être remplacée par une découpe du dataset en k-fold. Ensuite, les modèles entraînés par k-fold participent au résultat d’un modèle d’ensemble.
Conclusion
Kaggle étant une compétition, le score de 0.397 MAE est dépassé par d'autres techniques plus performantes (comme BiLSTM). Toutefois, pour un usage industriel, l’algorithme obtient de très bons résultats.



Aucun commentaire:
Enregistrer un commentaire