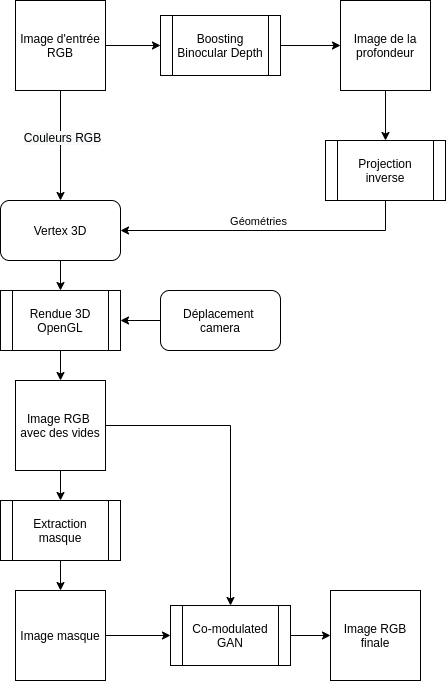
Estimation de la profondeur
L’information de profondeur n’est pas présente naturellement dans les photographies. Pour faire une estimation de la profondeur, il faut reconnaître des éléments dans une image et comparer leurs échelles sur des images référentielles qui contiennent la profondeur. Ainsi, une chaise semblable à plusieurs mètres sur une photo de référence peut nous donner l’information de sa profondeur sur la photo que nous cherchons à approfondir.
Voici l'étude retenue pour l’estimation de la profondeur:
Boosting Monocular Depth Estimation Models to High-Resolution via
Content-Adaptive Multi-Resolution Merging
Abstract
Neural networks have shown great abilities in estimating depth from a single image. However, the inferred depth maps are well below one-megapixel resolution and often lack fine-grained details, which limits their practicality. Our method builds on our analysis on how the input resolution and the scene structure affects depth estimation performance. We demonstrate that there is a trade-off between a consistent scene structure and the high-frequency details, and merge low- and high-resolution estimations to take advantage of this duality using a simple depth merging network. We present a double estimation method that improves the whole-image depth estimation and a patch selection method that adds local details to the final result. We demonstrate that by merging estimations at different resolutions with changing context, we can generate multimegapixel depth maps with a high level of detail using a pre-trained model.
https://arxiv.org/pdf/2105.14021v1.pdf [1]
Les algorithmes MiDaS [2] donnent de bons résultats sur les images mais manquent de finesse dans l’estimation des petits reliefs. Boosting Binocular Depth propose une solution pour évaluer les petits reliefs.
Par nature, les CNN sont capables de travailler sur plusieurs échelles, l’idée est donc de superposer les estimations de différentes parties de l’image à échelles différentes. Ainsi, l’image de profondeur gagne en précision et ce sont toutes les parties qui participent localement et globalement dans l’estimation.


(a) Fonctionnement de la méthode Boosting Binocular Depth : (b) Fournir l'image en basse et haute résolution au réseau, voici les résultats montrés avec MiDaS [2], et les fusionner pour obtenir une estimation de base avec une structure cohérente avec une bonne localisation des bordures. (c) Déterminons ensuite des différents morceaux (patchs) dans l'image. Ici, quelques patchs sélectionnés avec leurs estimations de profondeur. (d) Fusion des estimations de patch sur l’estimation de base de (b) pour obtenir notre résultat final à haute résolution. (source de l’image et de l’explication [1])




Quelques exemples d’estimation de profondeur avec Boosting Monocular Depth MiDas [1] .
Les résultats des algorithmes d’estimations donnent des images de profondeurs vraiment attrayantes. C’est un piège de nos sens que de penser que ces images sont justes. La vision humaine étant basée sur les contrastes, il est très difficile d’estimer la qualité de l’image de profondeur. Une zone sombre entourée de noir n’est pas perçues comme la même zone entourée de blanc. L'illusion d’Edward Adelson [3] montre que deux cases A et B de même couleur mais ayant des voisines de couleurs différentes sont perçues comme de couleurs différentes.
Notre difficulté à voir la progression d’intensité de profondeur nous empêche de bien vérifier la justesse des prédictions. Pour cela, nous pouvons considérer chaque point de l’image en 3 dimensions puis changer d’angle de vue pour voir si la profondeur est cohérente.
Projection inverse
La projection inversée répond à la question de savoir où se trouve, en trois dimensions, le point présent à l'écran en fonction de sa profondeur. Une photographie numérique est la mesure des rayons lumineux provenant du sujet, vue à travers un écran (les capteurs numériques) et l'œil centre de convergence de tous les rayons.

Les exemples ont été pris par un téléphone portable Pixel3a. Sa focale est de 28 mm soit 75.4° pour l’angle d’ouverture. Nous pouvons en déduire la position des points en 3d grâce à quelques règles de trigonométrie simples.



Exemple de projection inversée rendu dans Blender. La géométrie est enregistré dans un fichier au format stl
Changement de point de vue
Maintenant que les points sont en 3 dimensions, nous pouvons faire un rendu en déplaçant la caméra. Nous avons utilisé la librairie hardware accéléré OpenGL pour faire un rendu de la géométrie.


A gauche: une photo à tester. A droite: les profondeurs estimées par Boosting Binocular Depth.


Image de gauche: Simulation d’une caméra à l’emplacement de convergence des rayons lumineux. Cette vue ressemble à la photo d’origine. Cela permet de s’assurer que la projection inversée est juste. Image de droite: si l’on déplace la caméra, des manques d'informations font apparaître des trous dans la géométrie.
Rendu 3d et génération du masque
Pour générer le maillage en 3 dimensions de la géométrie, nous créons 2 triangles qui partagent 2 points en commun à partir de 4 pixels voisins sur l’image source. Un système de seuillage de distance maximum en Z permet de supprimer les triangles trop grands pour que le modèle soit cohérent. Le déplacement de la caméra fait apparaître des zones de manque d’information dans l’image. Nous allons extraire les zones vides dans un fichier image séparé.


A gauche: Image après le déplacement de la caméra. Les parties roses sont des endroits où il manque des données. A droite : L’image de masque extrait des parties roses de l’image de rendu.
Complétion de l’image
Nous allons utiliser un Generative Adversarial Networks pour compléter l’image dans les zones noires du masque. Pour compléter l’image, nous utilisons un Co-modulated Generative Adversarial Networks [4] pré-entraîné sur le dataset Places2 [5].
Large Scale Image Completion Via
Co-modulated Generative Adversarial Networks
Abstract
Numerous task-specific variants of conditional generative adversarial networks have been developed for image completion. Yet, a serious limitation remains that all existing algorithms tend to fail when handling large-scale missing regions. To overcome this challenge, we propose a generic new approach that bridges the gap between image-conditional and recent modulated unconditional generative architectures via co-modulation of both conditional and stochastic style representations. Also, due to the lack of good quantitative metrics for image completion, we propose the new Paired/Unpaired Inception Discriminative Score (P-IDS/U-IDS), which robustly measures the perceptual fidelity of inpainted images compared to real images via linear separability in a feature space. Experiments demonstrate superior performance in terms of both quality and diversity over state-of-the-art methods in free-form image completion and easy generalization to image-to-image translation.
https://arxiv.org/pdf/2103.10428.pdf [4]




En haut, à gauche: image source. Autres images: génération d'images à différentes positions






A gauche, les images sources. A droite après un déplacement de la caméra.
Interprétation des résultats
Les images semblent cohérentes visuellement si l’on regarde l’ensemble de l’image sans se concentrer sur les détails. Une fois focalisés sur les détails, nous pouvons constater des artefacts visuels.
La personne sur la photo a des postures étranges. Cela est dû à une mauvaise estimation des formes humaines.
Les éléments ajoutés par le Co-modulated GAN [4] sont cohérents quoique légèrement brouillés. Il est difficile de discerner le vrai du faux.
Améliorations possibles
L’estimation de la profondeur semble souffrir d’une dérive en Z de la profondeur. Pour améliorer les images nous pouvons compenser l’estimation de profondeur.
Le réseau Co-modulated GAN [4] prend en compte uniquement les pixels proches des zones à remplir pour compléter l'image. L’utilisation d’un algorithme DGGAN [6] pour fonctionner avec la profondeur pourrait rendre plus cohérent les images. Par exemple: https://arxiv.org/pdf/2012.03197.pdf
Références
[1] S. Mahdi H. Miangoleh, Sebastian Dille, Long Mai, Sylvain Paris, Yagız Aksoy,
Simon Fraser University, Adobe Research. Boosting Monocular Depth Estimation
Models to High-Resolution via Content-Adaptive Multi-Resolution Merging.
arXiv:2105.14021v1
[2] Rene Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun.
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset
transfer. IEEE Trans. Pattern Anal. Mach. Intell., 2020.
arXiv:1907.01341v3
[3] Illusion d’Edward Adelson http://www-bcs.mit.edu/people/adelson/illusions_demos.html
[4] Shengyu Zhao, Jonathan Cui, Yilun Sheng, Yue Dong, Xiao Liang, Eric I Chang, Yan Xu.
Large Scale Image Completion via Co-Modulated Generative Adversarial Networks.
arXiv:2103.10428
[5] Places2 dataset: http://places2.csail.mit.edu/
[6] Liangjian Chen, Shih-Yao Lin, Yusheng Xie, Yen-Yu Lin, Wei Fan, Xiaohui Xie,
University of California, Irvine, Tencent America, Amazon, National Chiao Tung University.
DGGAN: Depth-image Guided Generative Adversarial Networks for
Disentangling RGB and Depth Images in 3D Hand Pose Estimation.
arXiv:2012.03197v1